
一、论文背景及创新点
在论文中,作者注意到以下两个事实:
(1) 卷积神经网络的深度是决定超分性能的关键因素,但较深的网络很难训练。
(2) 低分辨率的输入和特征包含丰富的低频信息,这些信息在各个通道间被同等对待是不合理的,从而阻碍了CNN的表达能力
这里说一下低频信息的概念,低频信息指的是图像缓慢变化的部分。通俗讲,图像中边缘部分变化较大,称为高频信息。而边缘以内的部分缓慢变化,就称作低频信息。
于是作者提出了一种非常深的"RCAN"网络,用于超分问题,网络中比较值得关注的部分有两个:
(1) 提出了RIR(residual in residual)结构,用来构建非常深的能有效训练的网络。
(2) 提出了一种注意力机制(CA),通过考虑通道间的相互依赖关系,自适应地重新调整通道特征。

二、网络结构
1、整体结构
在介绍RCAN的网络结构之前,我们整体审视一下深度学习在超分领域的源头——SRCNN网络
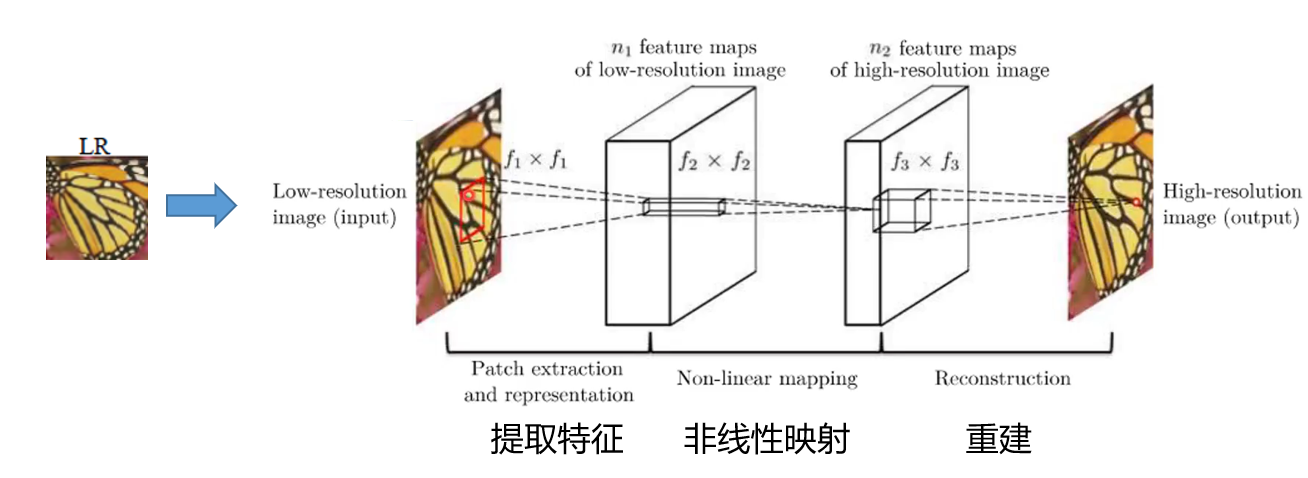
SRCNN网络是首先将深度学习体系应用到超分领域的一片论文。其思路非常简洁朴素,首先使用双三次插值方法将LR(低分辨率图像)放大到需要的尺寸,然后通过三个卷积层,最后得到超分后的图像SR
然后我们来看RCAN的网络结构
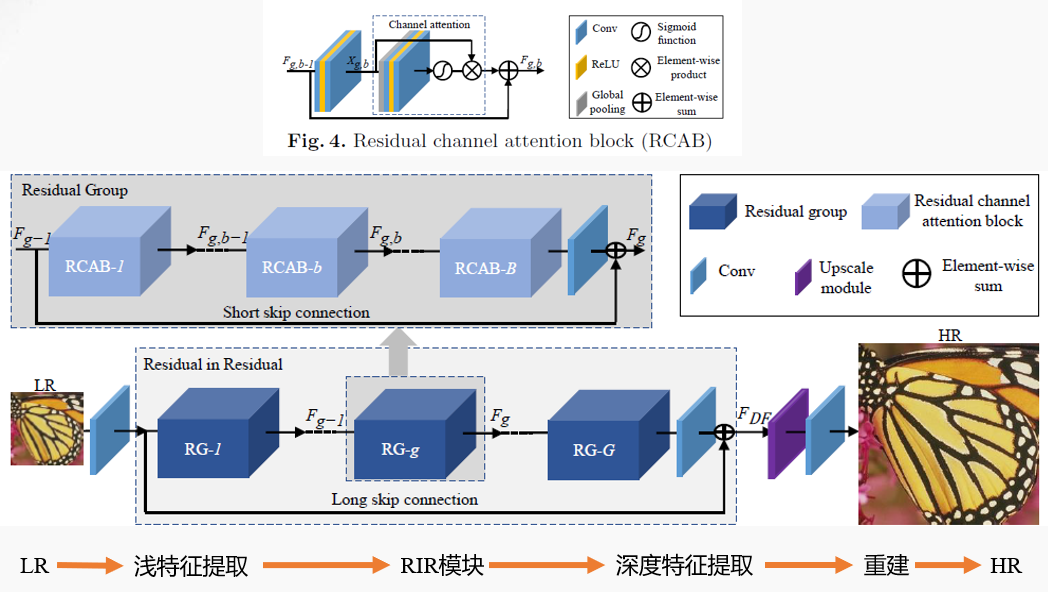
RCAN网络整体上也是这样的架构,但和SRCNN不同的是,RCAN并没有采用先放大LR的思路,而是直接将LR传入网络处理,最后输出前再将其重建为需要的尺寸。这种处理方法是借鉴了ESPCNN网络的思路与结果,可以降低计算量,同时得到更好的效果。
RCAN首先将LR图片传入网络,经过一个$3 \times 3 \times 64$、zero-padding的卷积层做浅特征提取,然后传入RIR模块。随后使用ESPCNN的方法对图片上采样,最后通过一个$3 \times 3 \times 3$、zero-padding的卷积层输出结果。
RIR模块内包括$G=10$个RG模块,通过10个RG模块后经过一个$3 \times 3 \times 64$、zero-padding的卷积层,与输入RIR模块前的图片信息做Long skip connection(LSC)长连接。
每个RG模块内包含$B=20$个RCAB模块,通过20个RCAB模块后经过一个$3 \times 3 \times 64$、zero-padding的卷积层,与输入RB模块前的图片信息做Short skip connection(SSC)短连接。
其中,SSC使得主网络可以学习剩余信息(residual information)。利用LSC和SSC,在训练过程中更容易绕过更丰富的低频信息。
输入RCAB模块的信息,首先通过一个$3 \times 3 \times 64$、zero-padding的卷积层,然后使用ReLU函数激活后再次通过一个$3 \times 3 \times 64$、zero-padding的卷积层,随后进入注意力模块,最后和输入RCAB模块前的信息做连接后输出对应信息。
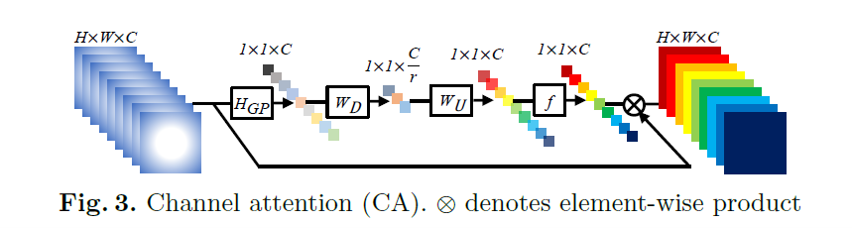
2、注意力模块
上面介绍了RCAN网络的整体结构。第一部分说了RCAN网络两大创新点,一个是RIR结构,一个是注意力模块。这里讲一下RCAN网络的注意力模块。
在此之前,我们先来看另一个网络——SE-Net
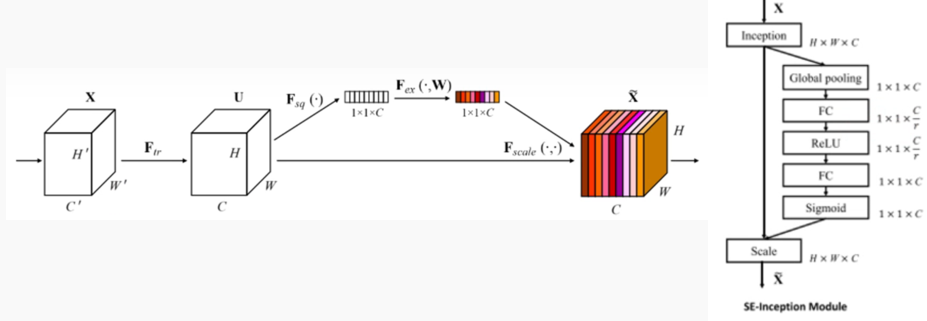
SE-Net是首先将通道注意力模块应用到深度学习的一篇论文,其结构如下:
(1) 先将输入信息进行一个全局平均池化,即对每一层所有元素取平均值作为该层的数值,将$H \times W \times C$的矩阵转化为$1 \times 1 \times C$的矩阵
$$z_{c} = H_{GP} (x_{c}) = \frac{1} {H \times W} \sum_{i=1}^{H} \sum_{j=1}^{W} x_{c}(i,j)$$
(2) 经过一个r倍的下采样、ReLU函数激活
(3) 经过一个r倍的上采样、Sigmoid函数激活
(4) 将得到的$1 \times 1 \times C$结果与输入注意力网络前的$H \times W \times C$矩阵做乘积,这就是通道权重。
然后回到RCAN网络,我们可以看到RCAN网络中使用的注意力模块其实就是SE-Net中涉及到的通道注意力方法。所以,RCAN论文所做的贡献其实大体可以概括为"将其他领域表现较好的注意力方法引入到了超分领域,进行了一系列的有机结合"
其代码如下
1 | # Channel Attention (CA) Layer |
3、损失函数与评价指标
RCAN在损失函数与评价指标这里没有过多改动,使用L1损失函数,使用PSNR以及SSIM作为评价指标。
EDSR论文中关于损失函数有一些评价:L2损失可以最大化PSNR,但L1损失可以提供更好的收敛性。感兴趣的可以去读一读。
三、环境搭建、代码复现
作者在其GitHub仓库中提供了源码,下载即可。
1、环境搭建
requirement.txt中已经将需要的包完整列出了,需要注意的有两点:
(1) python版本为3.6,注意在conda创建虚拟环境时正确设置python版本。
(2) pytorch版本比较老,是0.4.1版本的pytorch。
1 | # 依次执行以下指令 |
训练部分我是用的pytorch 0.4.1
但是我在推理部分无意中用了一次高版本的python和pytorch环境(python 3.8,pytorch 1.10.0),貌似没有问题,可以正常使用。
2、图片下采样方法
需要注意,下采样是使用matlab工具进行的。
所以如果你需要下采样自己的图片来做推理,请不要直接用python库进行下采样操作。如果使用不同的下采样方法,会导致推理出来的SR图片效果很差。
如果一定要避开matlab也不是不行,请参考bicubic_pytorch进行操作,这个方法下采样出来的图片和matlab效果接近。
"Consistent with MATLAB's imresize('bicubic'), with or without antialiasing"
下载bicubic_pytorch后,在"core.py"所在文件夹下新建一个python文件,内容如下:
1 | import core |
运行即可生成下采样后的LR文件
3、数据集
作者的GitHub仓库Readme部分有DIV2K数据集的下载地址,下载即可。
然后源码中附带了Set5测试集。
如果你还需要其他超分数据集,例如Urban100等,自己去网上找吧~
4、options.py文件主要参数含义
这里只介绍一些主要的参数
(1) '--n_threads': 加载数据时使用的线程数量,由于作者是在Linux上运行的代码,所以默认值不为1。如果你要在win下使用,请将此值设置为1
(2) '--dir_data': 数据集路径,需要注意路径格式问题。举个例子,我使用的是DIV2K数据集,
"D:\...\RCAN\DIV2K\bicubic\DIV2K\DIV2K_train_HR"中存放了1000张HR图片
"D:\...\RCAN\DIV2K\bicubic\DIV2K\DIV2K_train_LR_bicubic"中有三个文件夹"X2"、"X3"、"X4",分别存放了缩放相应倍数的LR图片
那么我的'--dir_data'应该设置为"D:\...\RCAN\DIV2K\bicubic"
这里一定要注意windows下路径表示方式和linux的区别
(3) '--data_train' '--data_test': 这两项是指定训练集和测试集的类别,默认为'DIV2K'。
其调用在"./RCAN_TrainCode/code/data/init.py"中的18、19行:
1 | module_train = import_module('data.' + args.data_train.lower()) |
根据args.data_train的值来调用"./RCAN_TrainCode/code/data"文件夹下的对应py文件,如果是默认值'DIV2K',那么就会调用'div2k.py'。
如果你想使用别的数据集,自己根据情况调整。
(4) '--n_train' '--n_val': 这两项是训练集和测试集的图片数划分。
默认是--n_train 800 --n_val 5,即在1000张图片里,取前800张作为训练集,取801-805张作为测试集。具体数字可以修改。
但比较有意思的一点是,作者在Issue中提出,自己并不是很喜欢在训练时引入测试集。比起这种做法,作者更喜欢在训练整体结束后再使用Set5作为测试集测试PSNR等数据。因为这样可以减少很多训练时间。
我在训练时使用的是前800张图片作为训练集,然后使用Set5的5张图片作为801-805张图片的测试集。
(5) '--ext': 这一项有两个数值可以选择:sep_reset和sep
事实上,模型在训练之前会先扫一遍数据集,将图片转换为二进制npy文件。sep_reset表示重新进行以上操作,一般用于更换/修改数据集图片时,或者第一次使用该数据集训练时;sep表示直接用已有npy文件不再重新生成,一般用于该数据集已经训练过的时候,此时使用sep可以省去准备图片的时间。
(6) '--scale': 倍率,取决于你是训练几倍的模型,这个倍率也决定了网络会加载哪一部分LR文件。上面提到了,"DIV2K_train_LR_bicubic"文件夹下有"X2"、"X3"、"X4"三个文件夹,scale设置为多少,网络就会加载对应文件夹下的下采样数据作为LR传入。
(7) '--pre_train': 预训练模型位置。如果不使用预训练模型,设置值为'.'即可。
(8) '--n_resblocks' '--n_resgroups' '--n_feats': 这三项是调整网络结构用的。分别是RCAB模块的数量,默认值20;RG模块的数量,默认值10;卷积核层数,默认值64。
(9) '--epochs': 训练轮数,根据作者所述,按照作者提供的参数训练1000轮后可以复现出论文的结果。
(10) '--batch_size': batch_size大小,即将多少张图片打包传入网络。默认值为16。
有趣的是,和其他模型不同,RCAN中batch_size影响的不只是训练速度,也影响了训练质量。我们看"RCAN_TrainCode\code\data\div2k.py"文件第15行代码:
1 | self.repeat = args.test_every // (args.n_train // args.batch_size) |
self.repeat指的是将训练集重复多少遍,test_every默认值1000,所以self.repeat = 1000 // (800 // 16) = 20
也就是说,训练集800张图片被重复了20遍共16000张图片传入网络。
换个角度讲,如果batch_size设置的比较低,那么self.repeat就会很小,最终影响训练结果。
考虑到batch_size为16,即每轮跑了1000个iters,200轮正好跑200000个iters,此时学习率下降一半。具体学习率相关参数见(12)和(13)
(11) '--test_only': 这个是在推理的时候用的。指的是只做推理不训练。其实仔细看RCAN代码结构可以发现,它的训练部分和推理部分用的是一套代码,全靠参数来决定程序走向。
(12) '--lr': 初始学习率
(13) '--lr_decay': 学习率多少个epochs减半,默认值200。
(13) '--save' '--load': 这个是结果保存的路径,以及加载模型的路径。注意区分这个'--load'和前面的'--pre_train'。我们看"RCAN_TrainCode\code\utility.py"的48-57行代码。
1 | if args.load == '.': |
从这里可以看到网络是如何定义存储路径的。保存路径是当前目录的上一级目录下的experiment文件夹。所以如果训练完模型去当前目录找结果那肯定是找不到的。
这种保存方式会存在一个问题,就是多次训练的时候,一定要注意先转移上一次训练的结果,不然······
我把这部分代码做了修改,使其更人性化一些,供参考:
1 | if args.load == '.': |
这样就把结果保存到了当前目录下的runs_latest文件夹下。这样每次跑完就把runs_latest更名为runsX,不会覆盖或者搞混了,也不用再去上一级目录找了。
(14) '--save_models': 保存所有中间模型。网络默认只会留下最后一次模型和最好一次模型。
(15) '--print_every': 这个参数指的是多少个batches后在控制台log一次当前进度。这里的数值看你自己其他参数的设置情况决定。需要注意一点,这里是"多少个batches"而不是"多少张图片",一个batches的图片数量是由batch_size决定的。
(16) '--save_results': 保存输出结果,这个是一定要加的。
四、可能出现的问题
1、scipy.misc读写图片报错
如果使用源代码直接运行,会出现scipy.misc的报错,原因是requirement.txt中scipy的版本过低。
解决方法:
找到代码中所有使用"misc.imread()"和"misc.imsave()"的部分,将其替换为"imageio.imread()"和"imageio.imsave()"即可。
2、CUDA: out of memory
不多说了,出现这个问题检查自己的option.py参数吧,什么事情都讲究量力而行嘛,为何不降低batch_size呢?
3、推理时不显示PSNR数值(显示PSNR: 0)
这个不是bug,仔细看代码可以发现,推理时压根就没将HR图像传入网络,只传入了LR图像,所以压根没有计算PSNR这一说。
一般来讲,超分领域的论文PSNR计算用的都是matlab,其计算方式和下面这种python直接计算是有区别的,matlab计算出来会偏大。
1 | def psnr1(img1, img2): |
所以为了复现论文结果或者统一标准,建议还是跑出结果后去matlab进行相关PSNR的计算,作者在源码中也给了相应的matlab文件。
如果非要在推理过程中显示PSNR的话也不是没有办法。我们看"RCAN_TestCode/code/data/myimage.py"文件第46行内容:
1 | return common.np2Tensor([lr], self.args.rgb_range)[0], -1, filename |
对比其他py文件相对应部分可以发现,这里return的三个东西分别是LR、HR和文件名,而推理环节压根就没有传入HR图像,传入的是-1作为占位符。
所以要想计算PSNR,我们要将HR图像传入。修改后的getitem函数如下
1 | def __getitem__(self, idx): |
即将原本options.py里的'--testpath'分成两部分,'--testpath_lr'和'--testpath_hr'然后用上面这段代码重新定义getitem函数。return的时候将HR图像一起送入dataloader。
当然,把'--testpath'分成两部分后,其他地方涉及到'--testpath'的也要相应改成'--testpath_lr',比如getitem下面的len函数就要修改。
其余地方这里就不再一一列举了,如果实在找不到可以尝试跑一跑看报错内容然后反过来再去定位。
4、推理时输出的图片不是SR而是HR
这个问题其实很难发现,出现的原因是保存结果部分有两个函数,分别是save_results和save_results_nopostfix。
"RCAN_TestCode\code\trainer.py"中默认调用的是save_results_nopostfix,使得后续输出的HR由于文件同名覆盖掉了之前的SR。在这种情况下如果再去计算PSNR结果可想而知(笑)。
解决方法:取消"RCAN_TestCode\code\trainer.py"中108行的注释,同时将109行注释掉,即改为下面这样:
1 | if self.args.save_results: |
然后打开"RCAN_TestCode\code\utility.py",将其中的save_results函数替换为:
1 | def save_results(self, filename, save_list, scale): |
五、对比与总结
1、RCAN的优势
我们先看这么一张有意思的结果图,这张图片来源于论文,作者并未着重强调但是这个结果展示的内容十分有意思:

我们可以看到在8倍任务的情况下,RCAN之前的几种方法不仅仅是结果模糊,甚至是给出了错误的结论。而RCAN的注意力结构使得网络成功的关注到了高频的线条信息。这是几种模型对比最为明显的一张结果图。
2、SAN网络
网络来源于论文《Second-order Attention Network for Single Image Super-Resolution》,同样可以找到开源的代码。SAN网络在RCAN的基础上改进了注意力模块,利用二阶信息协方差计算注意力。
区别在于RCAN使用全局平均池化,而SAN使用协方差计算二阶特征统计的attention
具体计算方法可以参考SAN论文及代码。
3、HAN网络
网络来源于论文《Single Image Super-Resolution via a Holistic Attention Network》,同样可以找到代码仓库。HAN网络引入了layer attention module通过获取不同深度特征之间的依赖关系,对不同层的特征分配不同的注意权重。
我们知道RCAN注意到的是各个通道间信息被平等对待是不合理的。而HAN注意到的是各个深度(经过不同次数卷积核)的信息被平等对待是不合理的,从而为不同深度的信息分配权重。
具体实现方法及网络结构图可以参考HAN论文及代码。
- 由 Etern 发表于 2022-11-29 ,添加 超分 注意力网络 标签,归类于 CV实践及论文阅读
- 本文链接: https://etern213.github.io/2022/11/29/Image-Super-Resolution-Using-Very-Deep-Residual-Channel-Attention-Networks/
- 版权声明: 本博客所有文章除特别声明外,均采用 Apache License 2.0 许可协议。转载请注明出处!